
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 일기장
- 모델평가지표
- Diffusion
- zero-shot classification
- 재활용 품목분류
- 머신러닝 사이클
- 백준
- pytorch
- 네이버부스트캠프
- object detection
- dp
- 객체탐지
- 스케치데이터셋
- 네이버부스트 캠프
- 11727번
- 회귀모델
- 네이버 부스트캠프
- imageclassification
- 학습장
- 코드트리
- 쓰레기분류
- 영수증 ocr
- 네부캠
- 스케치이미지
- 부스트캠프
- 다국어 ocr
- 1149번
- 타일링2
- 9095번
- Aimers
- Today
- Total
john8538 님의 블로그
다국어 영수증 OCR 본문
Github: https://github.com/boostcampaitech7/level2-cv-datacentric-cv-05
GitHub - boostcampaitech7/level2-cv-datacentric-cv-05: level2-cv-datacentric-cv-05 created by GitHub Classroom
level2-cv-datacentric-cv-05 created by GitHub Classroom - boostcampaitech7/level2-cv-datacentric-cv-05
github.com
본 내용은 네이버 부스트캠프 7기에서 진행한 세번째 프로젝트 내용에 대해 정리한 내용입니다. 모든 관련 저작권은 네이버 부스트캠프에 있음을 밝힙니다.
프로젝트 개요
이번 프로젝트는 다국어 영수증에서 글자를 검출하기 위해 OCR(Optical Character Recognition) 기술을 활용하는 것이 목표였습니다. 특히 데이터 중심(Data-Centric) 접근법을 통해 학습 데이터를 추가하고 수정하며 모델의 성능을 향상시키는 데 초점을 맞췄습니다. CV-05조는 다양한 실험과 데이터 라벨링을 통해 최적의 모델을 구축하고 최종적으로 높은 성능을 달성하는 것을 목표로 했습니다.
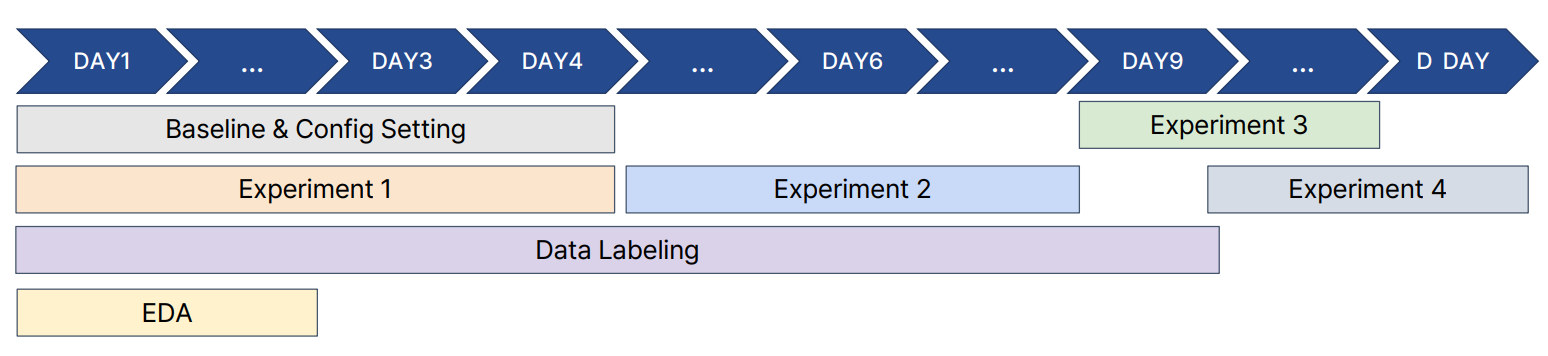
프로젝트 진행 과정
1. 초기 설정 및 EDA (Exploratory Data Analysis)
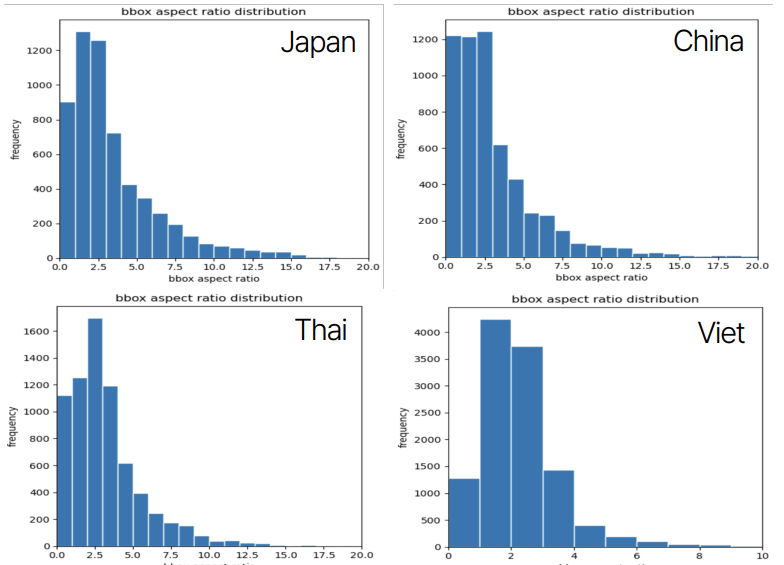
프로젝트 초기에는 데이터셋을 분석하고 이를 바탕으로 모델을 설계하기 위한 기초 작업을 진행했습니다. 데이터셋은 중국어, 일본어, 태국어, 베트남어 영수증으로 구성되어 있었으며 각 언어별로 100개의 이미지가 제공되었습니다.
- 데이터셋 특성 분석: 영수증 이미지의 특성을 분석한 결과 세로로 긴 이미지가 많았으며 특히 태국어와 베트남어의 경우 가로로 긴 이미지도 존재했습니다. 또한, Bounding Box(BBox)의 개수는 태국어와 베트남어가 중국어와 일본어보다 평균적으로 더 많았습니다.
- 학습에 방해되는 요소: 휘어진 영수증, 복잡한 배경, 촬영자의 그림자 등이 학습에 방해가 될 수 있는 요소로 확인되었습니다.



2. 모델 실험 및 가설 설정
프로젝트는 총 4차에 걸쳐 가설을 설정하고 실험을 진행했습니다.
1차 가설: 구분선 및 잘린 텍스트 삭제, 새로운 데이터셋 추가
데이터 라벨링 과정에서 직접 데이터셋을 검토하고 오류를 수정했습니다. 특히 구분선과 잘린 텍스트가 모델의 성능에 부정적인 영향을 미치는 것을 확인하고 이를 제거하는 작업을 진행했습니다.
이 과정에서 정제기준을 엄격하게 잡았습니다. 점선을 제외한 특수문자 패턴(++++,====)의 경우는 BBOX를 유지했습니다.
- 구분선 및 잘린 텍스트 삭제: Baseline 추론 시 구분선과 잘린 텍스트가 잘 인식되지 않아 이를 삭제했습니다. 구분선 BBox를 제거하고 원본 글씨에서 25% 이상 잘린 글씨의 BBox도 제거했습니다.
- 새로운 데이터셋 추가: 각 언어별로 50개의 새로운 데이터(구글링 노가다, 데이터셋 사이트... 등등)를 추가하여 데이터셋을 확장했습니다. 이를 통해 모델의 일반화 성능을 향상시키고 Validation loss를 개선할 수 있었습니다.

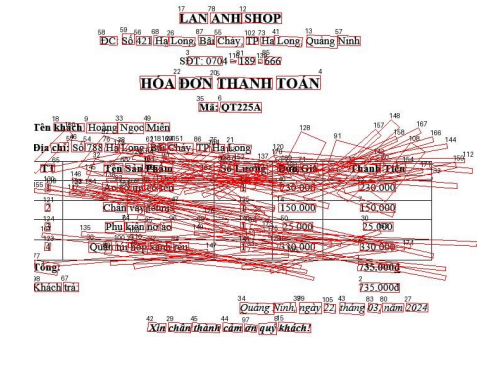




위의 사진이 삭제하기전, 아래 사진이 삭제한 이후입니다. 성능이 매우 향상됨을 보입니다. 그대신 점선을 인식하지는 못하죠.

점수또한 향상되었습니다. Precision, Recall, f1 score 모두 올라갔습니다.
그러나 새로운 Datasets을 추가했을때는 큰 향상이 있지는 않았습니다. 추가한 데이터가 다양성이 있지 않았거나, 모델의 학습에 불필요했다고 판단하였습니다.
2차 가설: 구분선 모델과 텍스트 모델의 구분, BBox 최적화
2차 가설에서는 구분선 모델과 텍스트 모델을 분리하여 학습시키고 BBox 크기를 최적화하는 실험을 진행했습니다.
- 구분선 모델과 텍스트 모델 분리: 구분선과 텍스트의 특성 차이를 고려하여 각각의 모델을 학습시켰습니다. 이를 통해 Recall을 향상시키고, 텍스트 매칭 정확도를 높일 수 있었습니다.
- BBox 크기 최적화: 작은 BBox와 큰 BBox의 문제점을 해결하기 위해, 라벨링 기준을 개선하고, 구부러진 텍스트는 다중 BBox를 적용하는 등의 방법을 사용했습니다.
3차 가설: Ensemble을 통한 성능 향상
3차 가설에서는 여러 모델의 결과를 Ensemble하여 개별 모델의 약점을 보완하고 성능을 향상시키는 실험을 진행했습니다.

- Ensemble 방법: 여러 모델의 결과를 IOU(Intersection over Union)를 기준으로 그룹화하고, 투표 수를 통해 최종 BBox를 결정했습니다.

- 결과: Ensemble을 통해 Precision, Recall, F1 score가 모두 향상되었습니다.
- iou 0.5 vote 2: Precision 0.9387, Recall 0.8821, F1 score 0.9095
- iou 0.4 vote 2: Precision 0.9384, Recall 0.8832, F1 score 0.9099
또한 앙상블을 진행한 결과에 의해 재 앙상블을 진행해보았는데요.

미미하게나마 향상한 모습을 보입니다.
4차 가설: 구분선 예측 모델 구축
4차 가설에서는 구분선만을 예측하는 모델을 구축하여 기존 OCR 모델과의 Ensemble을 통해 성능을 더욱 향상시키는 실험을 진행했습니다.
- 구분선 예측 모델: 구분선만을 BBox로 표기한 데이터셋을 활용하여 Fine-tuning을 진행했습니다. 이를 통해 구분선을 더 정확하게 예측할 수 있었습니다.


최종적으로 노이즈가 존재한 결과를 제외한 이후의 사진입니다.

결과: 구분선 예측 모델을 통해 중복 예측을 줄이고, 구분선 위의 지저분한 BBox 생성을 방지할 수 있었습니다.
이후 이 구분선 예측모델과 기존의 앙상블 모델을 합쳐 제출하였습니다.

public에서는 5등, private에서는 3등을 달성하였습니다.
프로젝트의 성과 및 아쉬운 점
성과
- 다양한 가설 설정과 실험: 다양한 가설을 설정하고 실험을 통해 최적의 모델과 파이프라인을 구축했습니다.
- Overfitting 없이 프로젝트 완료: Private 데이터셋에서도 좋은 성능을 보이며, Overfitting 없이 프로젝트를 완료했습니다.
- 높은 성능 달성: 최종적으로 Public LB Score 0.9196, Private LB Score 0.9196을 달성하며 높은 성능을 기록했습니다.
아쉬운 점
- 시간 부족: 계획했던 실험을 모두 완수하지 못했고 더 많은 Ensemble 조합을 시도하지 못한 점이 아쉬웠습니다.
- 구분선 이슈 해결 미흡: 구분선 예측 모델을 완벽하게 구축하지 못해 구분선 관련 이슈를 완전히 해결하지 못한 점이 아쉬웠습니다.
결론
이번 프로젝트를 통해 다국어 영수증에서 글자를 검출하기 위해 OCR 기술을 활용하는 과정을 체계적으로 경험할 수 있었습니다. 데이터 중심 접근법을 통해 학습 데이터를 추가하고 수정하며 모델의 성능을 향상시키는 과정에서 많은 것을 배울 수 있었습니다. 특히, GitHub를 통한 협업과 체계적인 실험 설계는 향후 프로젝트에서도 유용하게 활용할 수 있을 것입니다. 아쉬운 점도 있었지만 이를 통해 더 나은 프로젝트를 진행하기 위한 교훈을 얻을 수 있었습니다. 감사합니다.
'AI > Naver_Boostcamp AI Tech' 카테고리의 다른 글
| 재활용 품목 분류를 위한 Object Detection (0) | 2025.02.11 |
|---|---|
| Sketch 데이터셋을 활용한 Image Classfication (2) | 2024.09.29 |
| 회귀 모델 평가 지표 (0) | 2024.08.12 |
| 머신러닝 라이프사이클: 인공지능 프로젝트의 전체 과정 이해하기 (0) | 2024.08.12 |
| 텐서 연산 마스터하기: 기본부터 고급까지(2) (# 3일차-2) (0) | 2024.08.07 |



