
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 네이버 부스트캠프
- Diffusion
- 코드트리
- object detection
- zero-shot classification
- 영수증 ocr
- 모델평가지표
- 11727번
- 다국어 ocr
- 네이버부스트 캠프
- 재활용 품목분류
- 타일링2
- 쓰레기분류
- 1149번
- dp
- Aimers
- 네부캠
- 네이버부스트캠프
- 백준
- 스케치데이터셋
- 머신러닝 사이클
- 스케치이미지
- 학습장
- 부스트캠프
- 회귀모델
- 객체탐지
- imageclassification
- 9095번
- pytorch
- 일기장
- Today
- Total
john8538 님의 블로그
재활용 품목 분류를 위한 Object Detection 본문
Github: https://github.com/lexxsh/level2-objectdetection-cv-05
GitHub - lexxsh/level2-objectdetection-cv-05: level2-objectdetection-cv-05 created by GitHub Classroom
level2-objectdetection-cv-05 created by GitHub Classroom - lexxsh/level2-objectdetection-cv-05
github.com
본 프로젝트는 재활용 품목을 자동으로 분류하기 위한 Object Detection 시스템을 개발하는 것을 목표로 했습니다. 다양한 최신 딥러닝 모델들을 실험하고 앙상블하여 높은 정확도를 달성했으며, 특히 데이터의 특성을 고려한 augmentation 기법들을 적용하여 성능을 향상시켰습니다.

프로젝트 구조 및 협업방식
GitHub를 통한 협업
프로젝트의 효율적인 관리를 위해 GitHub를 활용한 체계적인 협업 시스템을 구축했습니다.
- 브랜치 전략
- main: 최종 배포용 브랜치
- develop: 개발 단계 브랜치
- 개인 브랜치: 각 팀원별 작업 브랜치
- 이슈 관리
- 기능 개발, 버그 수정 등의 작업을 이슈로 등록하여 관리
- 명확한 작업 내용과 진행 상황 공유
- 커밋 컨벤션
- Udacity 커밋 컨벤션을 활용하여 일관된 커밋 메시지 작성
- 기능별 명확한 커밋 메시지로 히스토리 관련
- 개선사항
- feature 브랜치 활용: 기능별 브랜치 관리로 더 효율적인 개발 가능
- 템플릿 활용: 이슈와 PR의 표준화된 양식으로 의사소통 개선
프로젝트 진행 과정
1. 초기 설정 및 EDA (Exploratory Data Analysis)
프로젝트 초기에는 데이터셋을 분석하고, 이를 바탕으로 모델을 설계하기 위한 기초 작업을 진행했습니다. 데이터셋은 한 이미지 안에 여러 개의 Bounding Box가 존재하며, 특히 10개 이상의 Bounding Box가 있는 이미지도 다수 존재했습니다. 또한, 클래스 불균형 문제가 있었는데, 일반 쓰레기(0), 종이(1), 플라스틱(5), 비닐(7) 등의 클래스가 상대적으로 많았습니다.


- Bounding Box 분포: 대부분의 Bounding Box는 이미지의 중앙에 위치해 있었으며, 배터리와 같은 작은 물체는 작은 Bounding Box를, 옷과 같은 큰 물체는 큰 Bounding Box를 가지고 있었습니다.
- 데이터 클렌징 필요성: 이미지 내에 Bounding Box가 많거나 겹치는 경우, 작은 Bounding Box를 학습하는 데 어려움이 있을 것으로 판단되어 데이터 클렌징의 필요성이 대두되었습니다.


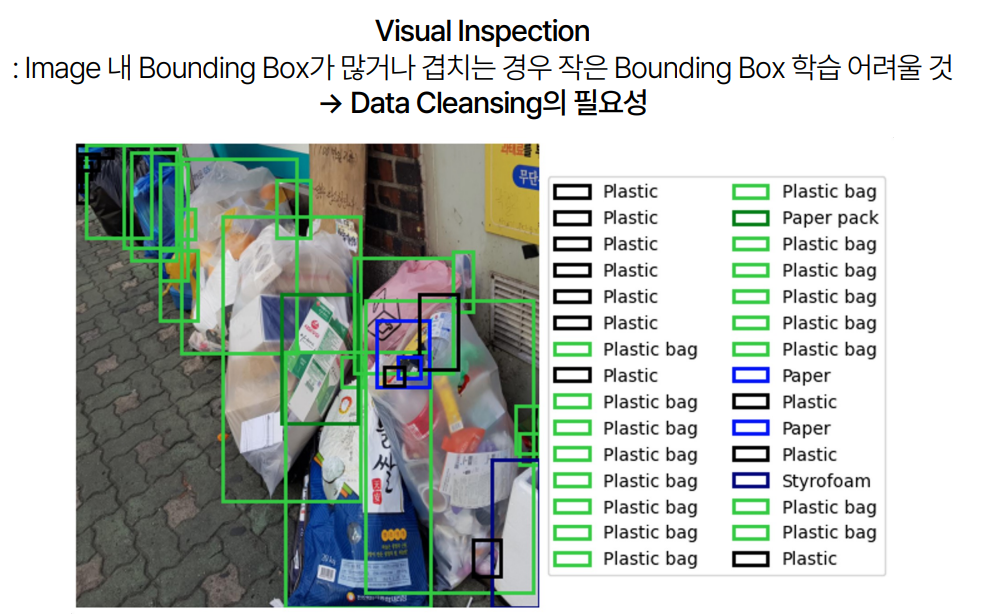
2. 데이터 라벨링
데이터 라벨링 과정에서 GitHub의 'labeling' 툴을 활용하여 직접 데이터셋을 검토하고 오류를 수정했습니다. 수정 기준은 다음과 같았습니다:
- Bounding Box가 15개 미만인 이미지만 수정
- Loose wrapping (느슨하게 감싸진 경우) 수정
- Unclear labels (명확하지 않은 라벨) 삭제
- Add labels (라벨이 누락된 경우 추가)
- Incorrect labels (잘못된 라벨) 수정
하지만, 데이터 포맷을 VOC에서 COCO로 변경하는 과정에서 문제가 발생하여 mAP가 0.001로 나오는 오류가 발생했습니다. 시간 부족으로 인해 해당 데이터셋을 사용하지 않기로 결정했습니다.




3. 모델 실험 및 가설 설정
프로젝트는 총 3차에 걸쳐 가설을 설정하고 실험을 진행했습니다.
1차 가설: SOTA 모델을 바탕으로 Baseline 모델 선정
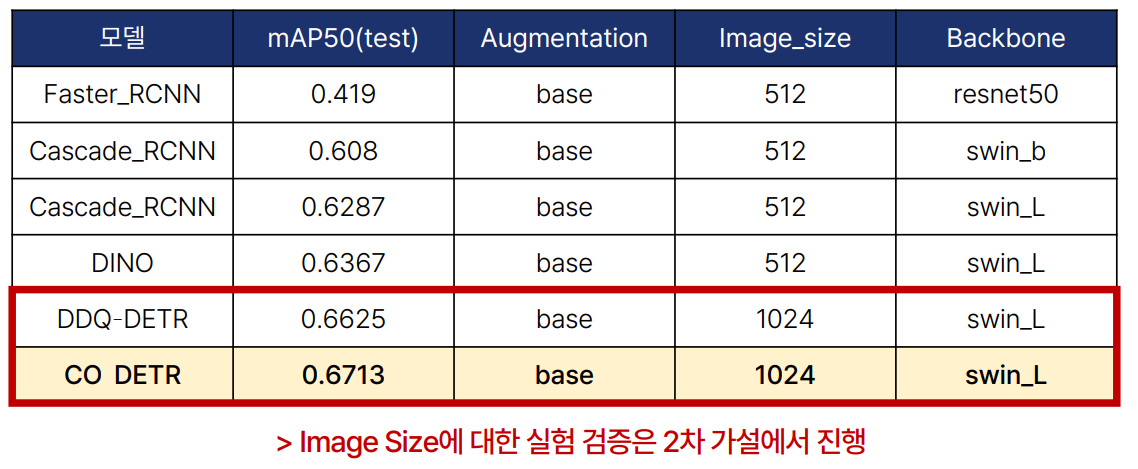
1차 가설에서는 SOTA(State-of-the-Art) 모델을 탐색하고, 이를 바탕으로 Baseline 모델을 선정했습니다. 주요 모델로는 Detectron2, mmdetection, YOLO 등을 실험했습니다.
- Detectron2: 최신 버전의 Config 파일 수정이 어려웠고, 학습은 성공했으나 Baseline과 유사한 성능(mAP 0.47)을 보여 추가 실험을 진행하지 않았습니다.
- mmdetection: CO-DETR 모델이 가장 좋은 성능을 보였습니다. Image Size에 대한 실험은 2차 가설에서 진행했습니다.
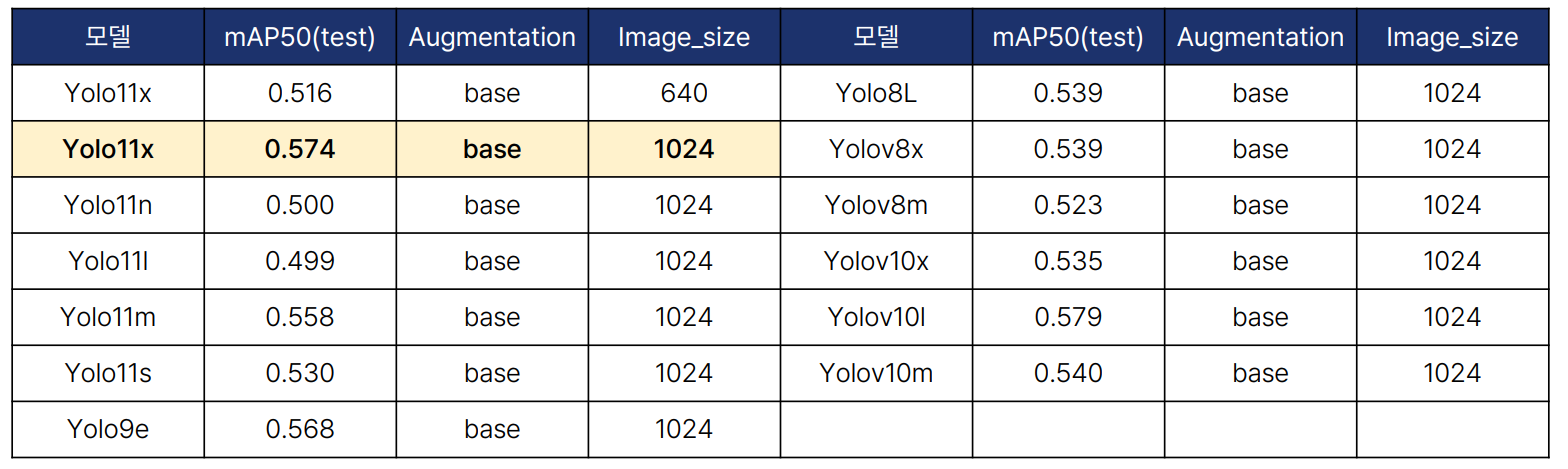
- YOLO: YOLOv8, YOLOv9, YOLOv10, YOLOv11 등 다양한 버전을 실험했습니다. YOLOv8은 CSPDarknet 개선 구조와 C2f 모듈을 도입하여 뛰어난 실시간 처리 능력을 보였습니다. YOLOv9은 GELAN 구조와 Programmable Gradient Information을 적용하여 추론 속도와 정확도를 높였습니다. YOLOv10은 EMO(Efficient Multi-scale Optimization)와 Dynamic Head를 도입하여 다양한 크기의 객체를 탐지할 수 있었습니다.
InterImage-H: CUDA 설정 관련 오류EVA: Mask Data가 필요하여 코드를 수정하였으나 실패ATSS(dyhead): Config 설정 오류로 낮은 성능이 나와 실패

이후 기존 데이터셋에서는 BBOX에 대한 정보만 존재하였기에 Mask Data를 추출하려 시도하였습니다. 구현은 완료하였으나, 시간부족과 실제 모델 적용의 오류가 있어 놔주었습니다.

2차 가설: Augmentations & TTA(Test Time Augmentation) 파이프라인 구축
2차 가설에서는 데이터셋의 특성을 반영한 Augmentations와 TTA를 활용한 Test 파이프라인을 구축했습니다.
데이터셋의 특징은 다음과 같습니다.
- Objects가 겹치고 가려진 경우 다수
- Bounding Box 대부분이 Image 중앙에 위치

이를 통해 가설 두가지를 작성했습니다.
Image의 해상도를 높이면 성능이 향상될 것이다!
특정 BBOX에 학습을 집중 시켜보자!
그후 이 가설에 맞게 실험을 진행하기로 하였습니다. 진행한 실험은 아래와 같습니다.
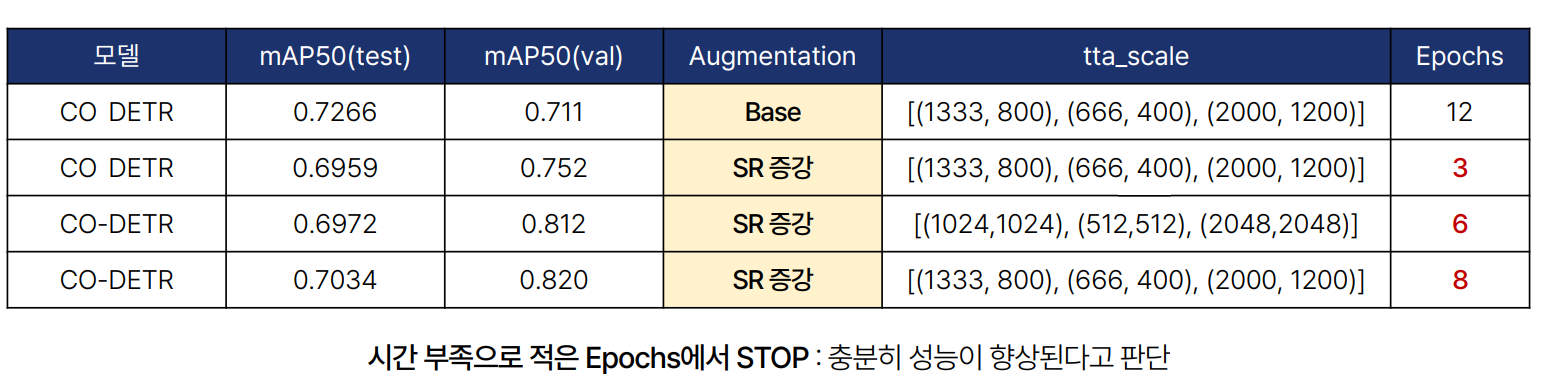
- Super Resolution 실험: 이미지 해상도를 높이는 것이 성능에 미치는 영향을 실험했습니다. Image Size가 커질수록 성능이 좋아지는 것을 확인했습니다.
- Crop 실험: RandomCrop, RandomCenterCrop 등의 기법을 활용하여 이미지를 무작위로 크롭하고, Bounding Box가 포함된 영역을 우선적으로 크롭했습니다. 이를 통해 원본 Train 데이터셋 4,883장을 Augmentation 후 29,126장으로 확장했습니다.
- Heavy Augmentation: Mosaic, RandomFlip, RandomAffine, PhotoMetricDistortion 등을 적용하여 다양한 크기의 객체가 모델에 잘 학습되도록 했습니다.
- TTA(Test Time Augmentation): Test 데이터셋에 Augmentation을 적용하여 다양한 크기의 객체를 효과적으로 인식할 수 있도록 했습니다. 특히, Multi Size Image를 활용한 TTA가 성능 향상에 도움이 되었습니다.
결과는 아래와 같습니다.

가설 1은 성공적으로 입증이 되었습니다!
이후 가설 2에 대해 진행하였는데요.
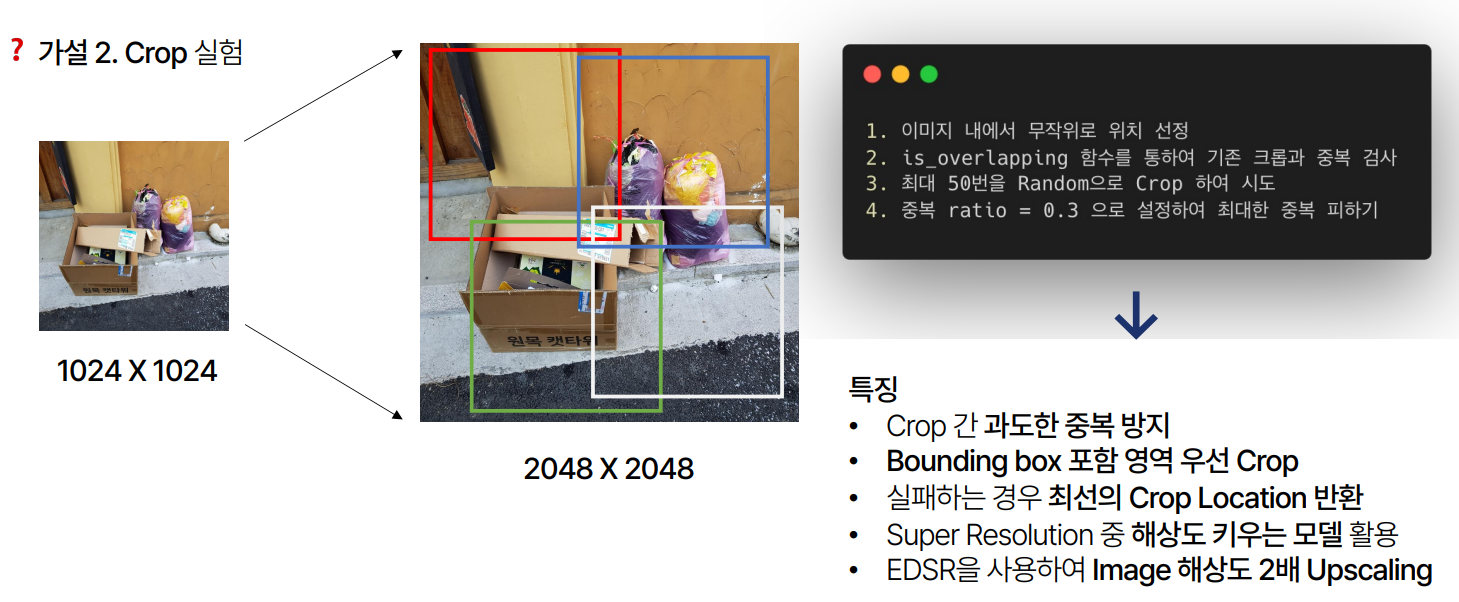
이런 방식으로 진행을 하였고 Random Crop을 활용하여 Offline Augmentation을 한결과 원본 데이터셋 4,883장에서 29,126장 까지 증가시켰습니다.
결과는 아래와 같습니다.
이후 추가적으로 다양한 Aumentations을 실험하였습니다.
저희는 Heavy Augmentation을 구성하였는데요. 대부분의 Object Detection에서는 많은 노이즈로 인한 다양한 Aumentations을 적용하는것이 결과가 좋다는 논문과 여러 캐글의 자료를 통하여 내린 결과입니다.


위 이미지와 시각적으로 확인해가며 진행하였습니다.
이에 대한 결과는 아래와 같습니다.

기본적으로 실험을 진행할때 동일한 조건을 갖추고 실험을 진행했어야하는데 그렇게 진행하지 못하였습니다. 이는 시간의 부족과 저희가 진행한 실험에 일부 오류가 존재함을 보여줍니다.
또한 모델별로 기본 config 설정과 모델구조가 다르기때문에 Aumentation을 다르게 적용했을때의 후 Ensemble 결과에 도움이 될 수 있을거란 생각도 일부? 하긴 했습니다..
마지막으로 TTA(Test Time Augmentation)을 활용한 실험을 진행해보았는데요, Test Datasets에 추론을 진행하기전에 이미지 사이즈에 대한 Augmentation을 적용해보았습니다.
결과는.....! 대성공이였습니다. 아주 높은 점수가 올랐습니다.
여러 논문과 Object Detection에 관련한 글에서 큰 효과가 있음을 입증하는 정보를 보고 시도하였습니다. 역시 리서치는 언제나 중요합니다.

3차 가설: IoU Threshold, TTA, Ensemble을 통한 성능 향상
3차 가설에서는 IoU Threshold, TTA, Ensemble 등을 활용하여 성능을 더욱 향상시키기 위한 실험을 진행했습니다.
- IoU Threshold 실험: IoU Threshold 값이 클수록 접촉 있는 객체 탐지에 유리하지만, 작은 객체 탐지에는 불리할 수 있다는 점을 확인했습니다. 적절한 IoU Threshold를 탐색하는 것이 중요했습니다.
- Ensemble: 여러 모델을 결합하여 성능을 높이는 실험을 진행했습니다. 특히, WBF(Weighted Boxes Fusion) 기법을 활용하여 DDQ, CO-DETR, Cascade R-CNN 모델을 Ensemble했을 때 가장 높은 성능을 보였습니다. 이 과정에서 앙상블을 하기전에 각 모델에 대한 결과를 Normalization을 진행했는데요, 이때 Min,Max 기법을 사용해 Confidence를 선형적으로 바꾸었습니다. 그후 Confidence가 0.1보다 낮은 bbox는 사용하지 않는 조건으로 진행했습니다.
(이 정규화도 성능효과에 아주 큰 기여를 했답니다!!)
Multi Size TTA: 앞에서 실험했던 TTA에 큰 성능효과가 있었기에 여러 사이즈를 가지고 조금더 다양하게 TTA를 진행했습니다. 가로/세로 비율이 다른경우 일정의 성능이 올랐지만 size를 더 추가한다고 성능이 오르진 않았습니다.
결론! 너무 다양하게 하는건 과하다!

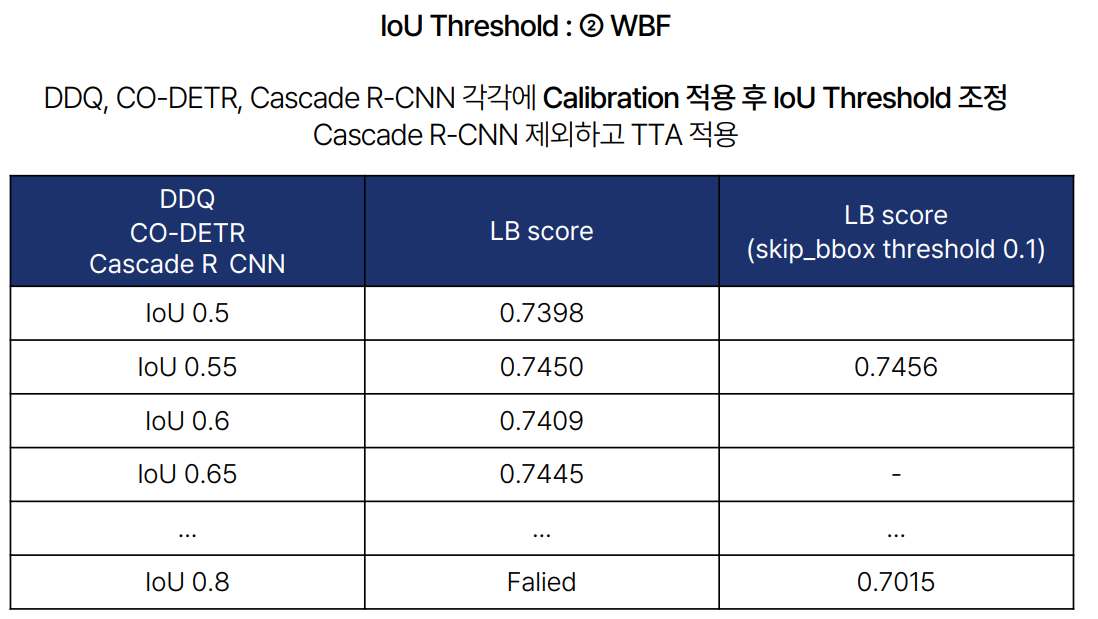
IoU를 일정이상 높이면 점수 측정에 실패하는 경우가 발생했습니다.
이 원인으로는 IoU가 너무높은 경우, BBOX가 매우 많이 남게 되는데 이 경우에 서버에서 csv 파일을 제대로 채점하지 못하여 제출 오류가 발생한것으로 추정했습니다.

다음은 앙상블 결과입니다. 최대한 다양한 조합을 시도하여 좋은 결과가 나오는 앙상블 조합을 파악해보았습니다. 이과정에서 앞서 실험한 Yolo 결과도 같이 앙상블 실험을 진행했습니다.


앙상블을 하는 과정에서 각 모델의 가중치도 조절할 수 있었습니다.
각 모델의 성능에 따라 가중치를 조절하는것이 의미가 있을것이란 가설을 마지막으로 세우고 앞과 동일하게 4가지 모델을 사용하였습니다.

최종적으로 마지막 많은 수의 모델을 앙상블하며 실험은 마무리 되었습니다.

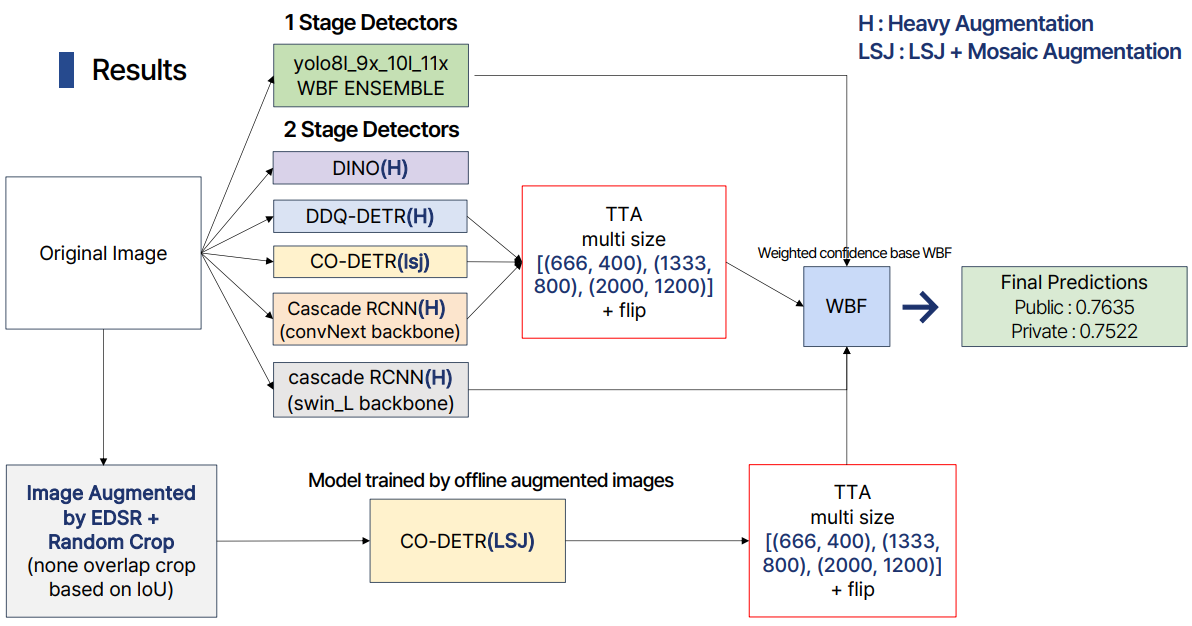
최종결과
최종적으로 다양한 모델을 Ensemble하여 Public LB Score 0.7635, Private LB Score 0.7522를 달성했습니다.
결과적으로 Public, Private에서 모두 1등을 달성했습니다.
CO-DETR, DINO, DDQ, Cascade R-CNN 모델을 Ensemble한 결과가 가장 높은 성능을 보였습니다.
저희가 프로젝트에 사용한 주요 모델은 다음과 같습니다.



최종 아키텍처입니다.
프로젝트 성과 및 아쉬운 점
성과
- GitHub를 통한 체계적인 협업: 이전 프로젝트의 피드백을 반영하여 GitHub를 통해 체계적으로 협업을 진행했습니다.
- 다양한 가설 설정과 실험: 다양한 가설을 설정하고 실험을 통해 최적의 모델과 파이프라인을 구축했습니다.
- 높은 성능 달성: 최종적으로 Public LB Score 0.7635, Private LB Score 0.7522를 달성하며 높은 성능을 기록했습니다.
아쉬운 점
- 시간 부족: 계획했던 실험을 모두 완수하지 못했고, 더 많은 Ensemble 조합을 시도하지 못한 점이 아쉬웠습니다.
- 백업 문제: 서버가 타져서 일부 결과물이 사라지는 문제가 발생했습니다. 이를 통해 백업의 중요성을 깨달았습니다.
결론
이번 프로젝트를 통해 Object Detection 기술을 활용하여 재활용 품목을 분류하는 과정을 체계적으로 경험할 수 있었습니다. 다양한 모델을 실험하고 데이터셋을 분석하며 최적의 파이프라인을 구축하는 과정에서 많은 것을 배울 수 있었습니다. 특히, GitHub를 통한 협업과 체계적인 실험 설계는 향후 프로젝트에서도 유용하게 활용할 수 있을 것입니다. 아쉬운 점도 있었지만 이를 통해 더 나은 프로젝트를 진행하기 위한 교훈을 얻을 수 있었습니다.
이상입니다! 감사합니다
'AI > Naver_Boostcamp AI Tech' 카테고리의 다른 글
| 다국어 영수증 OCR (0) | 2025.02.11 |
|---|---|
| Sketch 데이터셋을 활용한 Image Classfication (2) | 2024.09.29 |
| 회귀 모델 평가 지표 (0) | 2024.08.12 |
| 머신러닝 라이프사이클: 인공지능 프로젝트의 전체 과정 이해하기 (0) | 2024.08.12 |
| 텐서 연산 마스터하기: 기본부터 고급까지(2) (# 3일차-2) (0) | 2024.08.07 |



